- Maria Attarian
- Muhammad Adil Asif
- Jingzhou Liu
- Ruthrash Hari
- Animesh Garg
- Igor Gilitschenski
- Jonathan Tompson
Abstract
While significant progress has been made on the problem of generating grasps, many existing learning-based approaches still concentrate on a single embodiment, provide limited generalization to higher DoF end-effectors and cannot capture a diverse set of grasp modes. In this paper, we tackle the problem of grasping multi-embodiments through the viewpoint of learning rich geometric representations for both objects and end-effectors using Graph Neural Networks (GNN). Our novel method - GeoMatch - applies supervised learning on grasping data from multiple embodiments, learning end-to-end contact point likelihood maps as well as conditional autoregressive prediction of grasps keypoint-by-keypoint. We compare our method against 3 baselines that provide multi-embodiment support. Our approach performs better across 3 end-effectors, while also providing competitive diversity of grasps. Examples can be found at geo-match.github.io.
Example grasps
We train our method on a large number of diverse grasps spanning among 38 household objects and 5 different end-effectos: 2-finger, 3-finger, 4-finger, and 5-finger.

GeoMatch: Method
We propose a learning-based method that leverages GNN as generalized geometry encoders of objects and end-effectors and further predicts contacts for grasping in an autoregressive manner.
Our method architecture is the following:
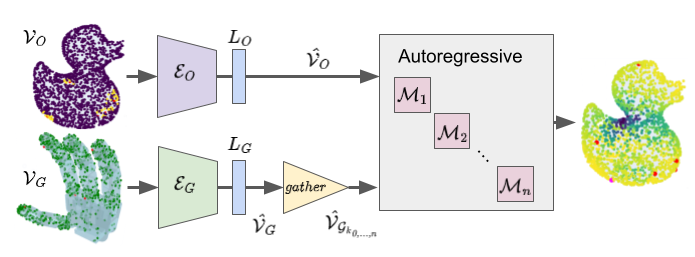
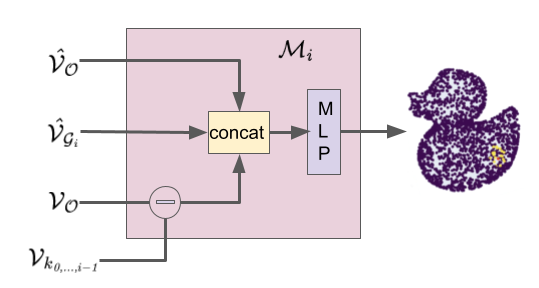
Point clouds of an object and end-effector are converted to graphs and passed through GNN encoders to obtain geometry embeddings that represent local geometry. The end-effector embeddings for a set of user selected keypoints are gathered and along with the object embedding, are used for contact prediction. This happens through an autoregressive setup where teacher forcing is applied to predict one keypoint at a time while also learning an independent distribution of object vertex to end-effector vertex contacts as an auxiliary task. Each autoregressive module is an MLP that operates on the difference map of all object points with the previous keypoint contact vertex, the end-effector keypoint embedding of the keypoint to be predicted, and the object embedding.
Demo